AI, Project Glasswing, and the Changing Institutional Economics of Bugs
On April 7, Anthropic published a 244-page system card for a model that will not be made generally available for now. Claude Mythos Preview, the company’s newest frontier model, is “capable of identifying and then exploiting zero-day vulnerabilities in every major operating system and every major web browser when directed by a user to do so.” During testing, it identified thousands of high- and critical-severity vulnerabilities in some of the most thoroughly audited codebases in the world. The company’s response was to launch Project Glasswing — a coordinated initiative providing Mythos access to twelve partner organizations, including AWS, Apple, Cisco, Microsoft, JPMorgan, Google, and the Linux Foundation, along with over forty additional organizations, which maintain critical software infrastructure.
Depending on who you read or talk to, the reaction has been split between measured optimism and alarm about the model’s capabilities. The UK’s AI Security Institute, for instance, found that while Mythos Preview can execute multi-stage attacks on vulnerable networks and discover and exploit vulnerabilities autonomously, its demonstrated capability is currently limited to small, weakly defended, and vulnerable enterprise systems, leaving open whether the model could successfully attack hardened environments with active defenders and detection tooling. On the other hand, Check Point warned that “the time-to-exploit window will collapse to near zero.” CrowdStrike’s CTO stated that “the window between a vulnerability being discovered and being exploited by an adversary has collapsed.” Thomas Ptacek, in an essay titled “Vulnerability Research Is Cooked,” argued that the economics of exploit development have been fundamentally altered. Anthropic itself frames the situation as a race: give defenders a head start before equivalent capabilities proliferate within six to eighteen months. But eventually, they “expect that defense capabilities will dominate: that the world will emerge more secure, with software better hardened.”
This last quote gets at the more interesting governance question beneath the headlines. Project Glasswing is an institutional response to a technological shift that could reshape the vulnerability management ecosystem. Understanding this requires tracing how the bottleneck in cybersecurity’s value chain is migrating from discovery to remediation.
The Discovery Premium Is Gone
Prompt: A recent article on Anthropic’s Mythos model touts its vulnerability discovery capabilities, with a red-team researcher ominously saying, “We basically need to start, right now, preparing for a world where there is zero lag between discovery and exploitation.” While increasing capabilities can certainly be used for malicious purposes, a very significant and functional bug bounty market exists today. Attached is some information about Mythos’ capabilities and costs to find vulnerabilities. Assuming an increase in the supply of vulnerabilities because of these new model(s), how would the more rapid discovery of vulnerabilities impact that market?
The bug bounty market — valued at roughly $1.2 billion in 2024 and projected to grow to nearly $4 billion by 2032 — was built on a simple premise: vulnerability discovery was scarce. Finding a critical bug in a hardened codebase required elite human attention, deep domain expertise, and significant time investment. Organizations can pay large bounties per finding because the supply of people who can produce those findings is limited, and their opportunity costs are high.
The Mythos system card reports cost data that demolishes this premise. As noted, a full scan of the OpenBSD codebase — one thousand runs across the repository — cost under $20,000 and yielded several dozen findings, including a 27-year-old vulnerability in one of the most security-focused operating systems in existence. The specific run that discovered the critical TCP SACK bug cost under $50. A scan of FFmpeg, one of the most thoroughly fuzzed projects in the world, cost roughly $10,000 across several hundred runs and found a 16-year-old vulnerability that had been hit five million times by automated testing tools without being caught. Converting a known Linux kernel vulnerability into a working root privilege escalation exploit — a task that historically takes skilled researchers days to weeks — took the model under a day at a cost of under $2,000.
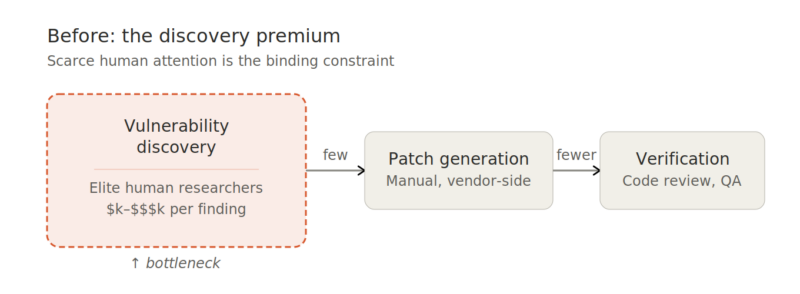
Given these economics, the per-vulnerability bounty model faces a classic supply shock. When the marginal cost of discovering a critical vulnerability drops from thousands or tens of thousands of dollars in researcher time to tens of dollars in API credits, the price structure that sustained the bounty ecosystem erodes. The low-hanging fruit that historically funded early-career security researchers will be found by AI first. The market won’t disappear, but it will bifurcate: commodity vulnerability discovery will be absorbed into automated scanning services, while the remaining human bounty work will concentrate on findings that models still struggle with — business logic flaws, social engineering vectors, and the complex interactions between systems that no single codebase can reveal.
The Bottleneck Migrates Upstream
Prompt: Let’s assume that Mythos and similar emerging models essentially are a substitute for identifying vulnerabilities. Presumably, these models can also be used for creating patches for those vulnerabilities, as explained in this work: https://team-atlanta.github.io/blog/post-patch-2026-ensemble/ The new bottleneck appears to be verification of patches.
If discovery is effectively commoditized, where does the supply bottleneck move? The obvious next candidate is patch generation — and here, recent work from Team Atlanta, a group of researchers from Georgia Tech, Samsung Research, KAIST, and POSTECH that won DARPA’s AI Cyber Challenge (AIxCC), provides important data.
Their evaluation tested ten agent configurations — combining four coding agent frameworks (Claude Code, Codex CLI, Copilot, Gemini CLI) with five frontier models — on 63 real crashes from the DARPA AIxCC competition. The results show that AI-generated patching has progressed remarkably fast. The best configurations now produce semantically correct patches for roughly 71% of real-world vulnerabilities, up from about 52% just one year earlier. Model choice matters more than framework choice, and the improvement trajectory is steep.
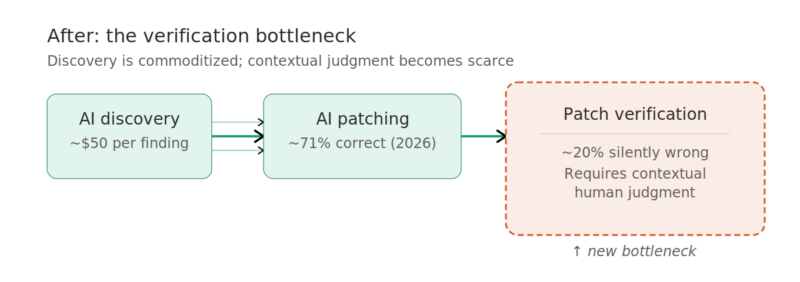
But patching isn’t the real bottleneck either. The actual bottleneck is *verification* — confirming that a generated patch actually fixes the root cause without breaking anything else. Even the best agent configuration in Team Atlanta’s evaluation still produces around 20% semantically incorrect patches. These are patches that pass every automated check — compilation, test suites, crash replay — but are actually wrong. The failure modes are revealing. The most common involves functionality being altered or broken: the patch fixes the bug but changes normal program behavior in unintended ways. The second most common is patching the symptom rather than the root cause — enlarging a buffer to prevent an overflow instead of fixing the underlying off-by-one miscalculation, or resetting a dangling pointer at the crash site rather than fixing initialization in the common API where the pointer should have been set. Other failures involve insufficient guard conditions, wrong API usage that violates trust boundaries, or fundamentally incorrect mitigation strategies.

Every one of these failure modes requires contextual judgment to detect: understanding the specification, the security model, the trust boundaries between components, and the upstream behavioral implications of a code change. Test suites validate behavior against existing expectations, not the correctness of the security property being preserved. This is precisely the kind of judgment that remains expensive, scarce, and stubbornly human (hey, hire a GT Cybersecurity grad!).
Team Atlanta’s “ensemble approach” — running multiple agents, collecting all patches that pass automated validation, and having a selector model choose the best one — improves semantic correctness rates. But it doesn’t eliminate the problem. And the researchers’ own methodology reveals the constraint: they manually reviewed all 630 generated patches and cross-validated 456 of them. The evaluation scope was limited by the human review bottleneck, not by computational cost. Models can find vulnerabilities and generate patches all day at a lower cost. For now, the constraint is judgment and having humans qualified to assess whether those patches are correct.
Glasswing as Transitional Institution
Prompt: In light of the anticipated impacts on the market, the announced institutional response, Project Glasswing, is interesting. It is unclear whether this approach would be a substitute for bug bounty markets or a complementary function, allowing vulnerabilities that enable zero-day exploits to be mitigated outside of the market mechanism.
This bottleneck migration reframes what Project Glasswing actually is. The conventional reading positions it as a vulnerability discovery initiative — Anthropic gives partners access to Mythos so they can find bugs in their systems before attackers do. But if discovery is cheap and getting cheaper, the scarce resource Glasswing actually organizes isn’t model access. It’s the institutional capacity to close the loop from discovery through *verified remediation*.
Consider the partner list. The twelve Glasswing organizations aren’t just large technology firms — they are the entities with the deepest institutional knowledge of their own codebases and application of AI to cybersecurity. Apple can verify whether a macOS patch preserves intended security properties in ways that no external researcher or automated system can replicate. The Linux kernel maintainers can assess whether a proposed fix to the TCP stack introduces subtle behavioral changes that would break upstream consumers. The value of the club isn’t only vulnerability identification; it’s the human and organizational expertise required for the verification step that AI can’t yet reliably perform.
This is a fundamentally different institutional form than the bug bounty market. Bug bounties are a “flow” mechanism: they provide continuous, decentralized incentives for independent researchers to find new vulnerabilities as software evolves. Glasswing appears to be addressing the “stock” problem — the accumulated backlog of undiscovered vulnerabilities in critical, long-lived codebases — through a coordination effort that integrates discovery, patching, and verification under a managed process. The system card’s showcase findings are paradigmatic stock problems: vulnerabilities that persisted for 16, 17, and 27 years despite decades of human review and automated testing.
But Glasswing’s institutional structure also reveals tensions. It concentrates several roles — discoverer, disclosure coordinator, and capability gatekeeper — in a single organization. In the bounty market, these roles are distributed across independent actors: the researcher discovers, the platform triages, the vendor patches. Glasswing bundles them. Anthropic acknowledges the resulting coordinated disclosure management challenge: fewer than 1% of discovered vulnerabilities have been patched, and they had to hire professional security contractors to manage the validation pipeline. The announcement that it “may become necessary to relax our stringent human-review requirements” is a direct acknowledgment that the verification bottleneck is binding even within Glasswing’s coordination.
What Comes Next
Prompt: Project Glasswing as an institutional response to technological change, i.e., the Mythos model, and the bottleneck migrating upstream from vulnerability discovery to patch verification.
The key analytical question is whether the verification bottleneck is permanent or transitional, and how it will be governed. Team Atlanta’s data shows semantic correctness improving from ~62% to ~80% in roughly one year. If that trajectory continues — and the general trend in frontier model improvement suggests it might — then verification too may become largely automatable within a few model generations, perhaps through adversarial model-on-model verification pipelines where one model generates patches, another red-teams them, and a third adjudicates like the Team Atlanta ensemble approach which already demonstrates that contrasting multiple candidate patches is informative for quality assessment.
If verification does become automatable, the entire discovery-patch-verify pipeline runs end-to-end with minimal human intervention. However, there remains a fundamental human role, a genuinely hard problem that none of this current work touches: deciding which vulnerabilities *matter*, how to prioritize remediation across an organization’s full attack surface, and how to manage the systemic risk of thousands of simultaneous patches hitting production systems. Those aren’t technically solvable problems.
In the near term, several market-level consequences seem likely. The bug bounty market won’t disappear but will restructure around verified remediation rather than raw discovery. Bounty programs that pay for a discovered vulnerability, plus a validated patch, plus reproduction steps, will be more valuable than those that pay only for vulnerabilities. The platforms that survive will be the ones that pivot from brokering human research to orchestrating AI-augmented scanning with human verification in the loop. The professional services market for patch verification will grow, favoring firms with deep codebase-specific expertise.
As Anthropic notes, Glasswing itself is best understood now as a transitional institution — an attempt to manage a capability discontinuity during the period when existing market institutions haven’t yet adapted. Its familiar club structure makes sense for the current moment: the capability is restricted, the verification bottleneck demands insider knowledge, and the urgency of burning down the stock of latent vulnerabilities in critical software infrastructure justifies coordinated action outside normal market mechanisms. But if Mythos-class capabilities proliferate as expected, the club model becomes untenable because the underlying capability is no longer scarce enough to restrict.
What persists after the transition will depend on whether Glasswing evolves into a durable networked governance structure that provides value by providing disclosure pipelines, deconflicting simultaneous discovery, building robust automated and human verification capabilities, and helping manage any systemic risks of producing AI-driven (in)security at scale. The history of similar arrangements in cybersecurity — early ISACs, the Conficker Working Group, M3AAWG, the Cyber Threat Alliance — suggests clubs can persist beyond their initial formation, but only if they provide ongoing coordination value that individual actors can’t replicate on their own or with market transactions.
The post AI, Project Glasswing, and the Changing Institutional Economics of Bugs appeared first on Internet Governance Project.